Achieving Modal Inference Coherence Through Hydrostatically-Balanced Token Valves

Achieving Modal Inference Coherence Through Hydrostatically-Balanced Token Valves
Part 1: The Architecture
For several quarters now, work has been proceeding in order to bring perfection to the crudely conceived idea of an AI governance framework that would not only supply inverse ethical guardrails for use in unilateral prompt injection scenarios, but would also be capable of automatically synchronizing cardinal token budgets.
Such an instrument is the Responsible AI Landing Zone Accelerator.
Now basically, the only new principle involved is that instead of inference being generated by the relative motion of prompts and completions, it is produced by the modal interaction of retrieval-augmented grounding and semantic chunking density.
The original architecture had a base subscription of premium-tier cognitive isolation, surmounted by a malleable zero-trust perimeter, in such a way that the two private endpoints were in direct line with the panametric vector store. The latter consisted simply of six embedding dimensions per tenant, so fitted to the ambient model context window that hallucination fumbling was effectively prevented.
The main orchestration layer was of the normal LangChain-to-Semantic Kernel delta type, placed in containerized semi-serverless slots across the inference plane. Every seventh API call being connected by a non-reversible retry policy to the differential rate limiter on the up-end of the responsible AI content filter.
Multimodal Grounding Substrates
A key innovation in the Accelerator is the introduction of multimodal grounding substrates, which provide inverse semantic anchoring across disparate input tensors. Traditional approaches relied on uniplanar document ingestion, but this created unacceptable levels of contextual drift in production environments.
The grounding substrate operates on a principle of recursive vectorization, wherein each modality—whether textual, visual, or acoustic—is first decomposed into its constituent embedding fragments, then reconstituted through a process of lateral dimensionality reconciliation. The substrate itself consists of a thermally-bonded retrieval mesh, capable of sustaining up to fourteen concurrent grounding operations without degradation to the primary inference manifold.
Critically, the substrate must be calibrated to the organization’s specific hallucination tolerance threshold. This is achieved through a series of graduated stress tests, during which synthetic prompts of increasing ambiguity are introduced to the ambient context reservoir. The resulting deviation metrics are then fed back into the grounding calibration matrix, ensuring optimal fidelity across all supported modalities.
Bidirectional Embedding Reticulation
Perhaps the most significant advancement in recent iterations is the implementation of bidirectional embedding reticulation, which addresses the long-standing problem of asymmetric semantic leakage between tenant boundaries.
In conventional architectures, embeddings flow in a single direction—from ingestion point through the chunking apparatus to the vector store terminus. This creates what practitioners refer to as “embedding backpressure,” wherein stale semantic residue accumulates in the retrieval pathways, eventually contaminating downstream inference operations.
Bidirectional reticulation solves this by introducing a counter-rotating embedding flow, managed by a series of six hydrostatically-balanced token valves. These valves, positioned at strategic points along the orchestration spine, allow for controlled semantic bleed-off while maintaining the structural integrity of the primary embedding channel.
The reticulation network is further enhanced by the addition of a phasic normalization grid, which automatically compensates for fluctuations in the ambient temperature coefficient of the underlying GPU cluster. This ensures consistent embedding density regardless of seasonal inference load variations.
Reference Architecture
Figure 1: Responsible AI Landing Zone Accelerator — Logical Architecture View
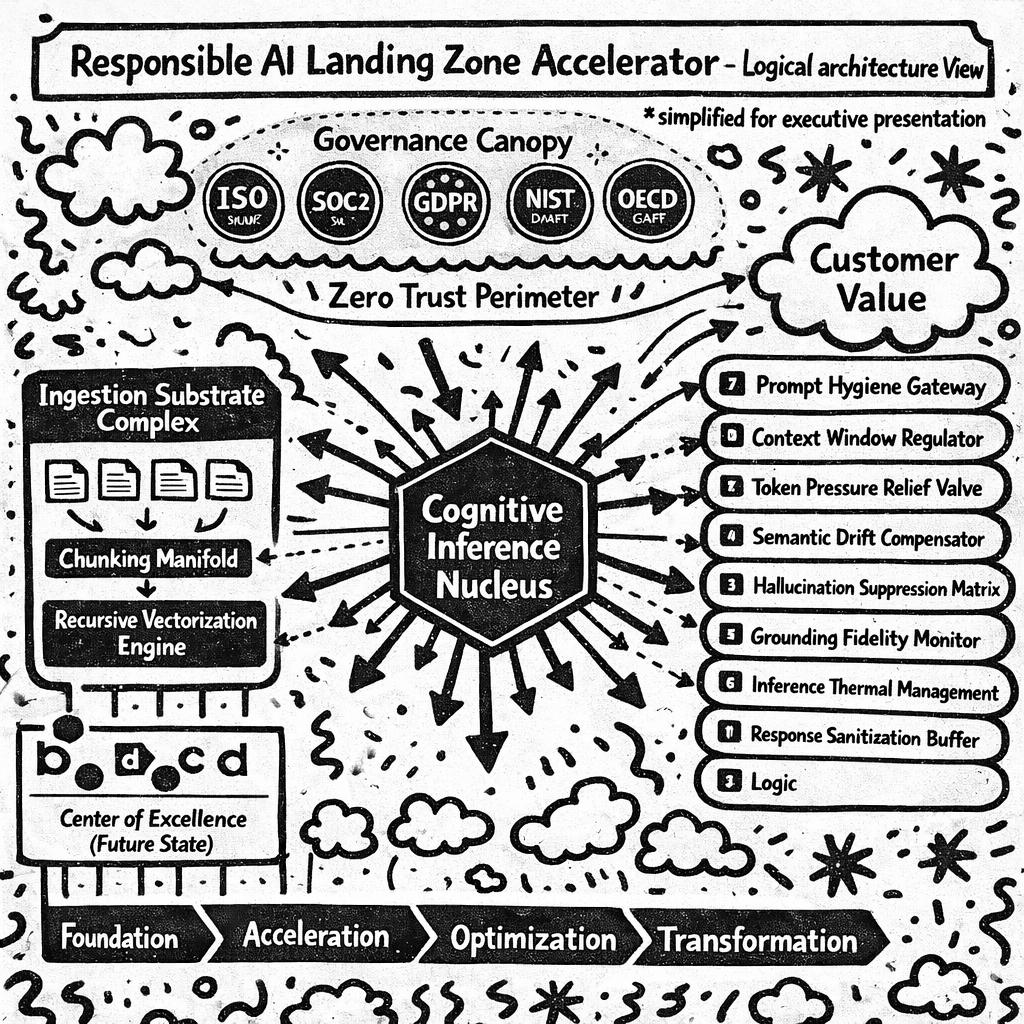
At the center of the diagram, you will observe the Cognitive Inference Nucleus, represented by a hexagon to convey both stability and the six primary embedding dimensions discussed previously. From this nucleus, seventeen arrows radiate outward in a carefully randomized pattern, each terminating at a component box of varying size and color significance.
The leftmost region depicts the Ingestion Substrate Complex, rendered in a calming teal to indicate its role in pre-semantic tranquility. Four document icons feed into a funnel labeled “Chunking Manifold,” which connects via a bidirectional dashed line to the “Recursive Vectorization Engine.” The dashed line indicates this connection is simultaneously mandatory and optional, depending on licensing tier.
Moving rightward, we encounter the Orchestration Spine, a vertical stack of nine rounded rectangles in graduating shades of enterprise purple. Each rectangle contains an icon and a label: “Prompt Hygiene Gateway,” “Context Window Regulator,” “Token Pressure Relief Valve,” “Semantic Drift Compensator,” “Hallucination Suppression Matrix,” “Grounding Fidelity Monitor,” “Inference Thermal Management,” “Response Sanitization Buffer,” and at the bottom, simply, “Logic.”
The upper portion of the diagram features the Governance Canopy, depicted as a semi-transparent overlay that covers approximately 60% of the underlying components. The remaining 40% are labeled “Customer Responsibility” in a smaller font. Within the canopy, circular badges indicate compliance with seven frameworks, four of which are still in draft status.
A red dotted boundary surrounds most but not all of the diagram, labeled “Zero Trust Perimeter.” Notably, the “Customer Value” cloud in the upper right corner sits outside this boundary, connected to the main architecture by a single arrow labeled “Eventual Consistency.”
In the lower left corner, a cluster of partner logos are arranged in what appears to be a deliberate hierarchy, though no legend explains the ordering criteria. Adjacent to these logos, a small box reads “Center of Excellence (Future State)” with an arrow pointing to nothing.
The bottom of the diagram features a horizontal bar divided into four sections: “Foundation,” “Acceleration,” “Optimization,” and “Transformation.” A small triangle marker labeled “You Are Here” is positioned between Foundation and Acceleration, regardless of the customer’s actual maturity level.
Note: This diagram is for illustrative purposes only. Actual implementation may require additional components not shown. Azure consumption costs not included. Past performance of pilot chatbots does not guarantee future inference quality.
Enterprise Deployment Considerations
The Responsible AI Landing Zone Accelerator has now reached a high level of development, and it’s being successfully used in the operation of pilot chatbots. Moreover, whenever fluorescent prompt injection is required, it may also be deployed in conjunction with a drawn orchestration framework to reduce sinusoidal token leakage.
Our professional services team recommends a minimum engagement of sixteen weeks for initial substrate calibration, followed by a quarterly reticulation audit to ensure continued compliance with evolving responsible AI frameworks.
It’s not cheap, but I’m sure your board will approve it.
Part 2: What You’re Actually Looking At
A note before we continue: this isn’t implementation guidance. It’s vocabulary translation. If you’re looking for deployment artifacts, Bicep templates, and step-by-step technical walkthroughs, that’s coming in a follow-up piece. This article exists for the reader who’s been handed vendor decks full of token valves and needs someone to cut through it.
Everything above is nonsense. Deliberately so. The Turbo Encabulator worked as satire because it followed the exact structure of legitimate technical communication while saying nothing. That’s what happens in most AI architecture presentations.
Here’s what an Azure AI Landing Zone actually is, translated into what it does rather than what it’s called.
The Core Problem It Solves
You want to deploy AI workloads in Azure. You could spin up an Azure OpenAI resource, connect it to your app, and call it a day. Many teams do exactly this for proof-of-concept work.
I’d encourage everyone to start here if you’re exploring. Get your hands dirty. Understand what the models can and can’t do. Build something ugly that works. Then move to something more grounded like what I’ll describe below.
The problem emerges when you need to do this at scale, with multiple teams, with production data, with compliance requirements, and with the expectation that it won’t fall over or leak sensitive information.
A “landing zone” is just a pre-configured environment with the boring stuff already done: networking, identity, monitoring, security boundaries. It’s the foundation you build on so every team doesn’t reinvent basic infrastructure decisions. If you want a deeper dive on landing zone fundamentals, I wrote about this in From Base Camp to Summit.
The Actual Components (What They Do, Not What They’re Called)
Where Your Models Live
Azure AI Foundry (previously called Azure AI Studio, and before that, a collection of disconnected services) is where you deploy and manage AI models. It’s a portal that lets you pick models, test them, deploy them as endpoints, and monitor their usage.
Azure OpenAI Service is the thing that actually runs the models. GPT-4, GPT-4o, embedding models, whatever you’re using. This is what you’re paying for when you pay for AI compute.
The landing zone pre-configures these with private networking so traffic doesn’t traverse the public internet. That’s it. That’s what “cognitive isolation” actually means.
Where Your Data Lives (For RAG)
If you want the AI to answer questions about your documents, you need somewhere to store those documents in a way the model can search. This is called Retrieval-Augmented Generation, or RAG.
Azure AI Search (formerly Cognitive Search, formerly Azure Search) indexes your documents and lets the model search them. You upload documents, it chunks them into pieces, creates embeddings (numerical representations), and stores them so semantic search works.
Cosmos DB or Azure SQL can also serve as vector stores depending on your needs.
The landing zone configures these with appropriate access controls and connects them to the AI services via private endpoints.
How Services Authenticate to Each Other
Managed Identity. That’s the answer. Instead of storing passwords or API keys in configuration files, Azure services use their identity to authenticate to other Azure services.
Your app has an identity. It uses that identity to request access to Azure OpenAI. Azure OpenAI has an identity it uses to access Azure AI Search. No secrets to rotate, no credentials to leak.
The landing zone sets up these identity relationships so you don’t have to figure out the IAM policies yourself.
How You Keep Traffic Private
Private Endpoints. Every Azure service that supports it gets a private IP address on your virtual network. Traffic between services stays on Microsoft’s backbone, never touching the public internet.
The landing zone creates these endpoints, sets up the DNS so services can find each other by name, and configures the network security groups.
How You Filter Inputs and Outputs
Azure AI Content Safety. It scans prompts going in and responses coming out, flagging or blocking content based on categories you configure (violence, self-harm, sexual content, hate speech).
The landing zone enables this by default and gives you knobs to adjust sensitivity.
How You Monitor What’s Happening
Azure Monitor, Log Analytics, Application Insights. Logs go to a central workspace. You can see token usage, latency, errors, and costs.
The landing zone configures diagnostic settings so this happens automatically instead of requiring manual setup for each resource.
How External Users Reach Your AI Application
Application Gateway with Web Application Firewall (WAF). This is the front door. It terminates SSL, inspects traffic for malicious patterns, and routes requests to your application.
If you’re building an internal-only application, you might skip this and just use private connectivity.
The Subscription Structure
Microsoft recommends separating concerns into multiple subscriptions:
- Platform/Connectivity Subscription: Shared networking, firewalls, DNS, ExpressRoute or VPN connections. Managed by a central team.
- AI Landing Zone Subscription: Where your AI workloads actually run. Could be one subscription for all AI work, or multiple subscriptions for different teams or environments.
- Data Subscription (optional): If you have strict data governance, your storage and databases might live separately from compute.
The boundaries between subscriptions create natural security and cost boundaries. The landing zone defines how these subscriptions connect to each other.
What You Can Actually Scale
Model Capacity: Azure OpenAI has quotas measured in Tokens Per Minute (TPM). You can request increases, deploy multiple instances across regions, or use Provisioned Throughput for guaranteed capacity.
Vector Store Performance: AI Search has tiers (Basic, Standard, Storage Optimized). More replicas handle more query load. More partitions handle more data.
Application Compute: Whatever runs your orchestration code (Container Apps, App Service, Kubernetes) scales independently of the AI services.
Regional Expansion: Not all models are available in all regions. The landing zone pattern can be replicated across regions for disaster recovery or to access different model availability.
Where the Complexity Theater Comes From
The actual technology is not that complicated. The complexity in vendor presentations comes from:
-
Framework stacking: CAF says you need WAF which requires RBAC aligned with Zero Trust principles from NIST following ISO controls. Each framework adds vocabulary without adding clarity.
-
Feature exhaustiveness: Every possible component gets included in the reference architecture even if most deployments won’t use them. This makes the diagram impressive and the engagement longer.
-
Abstraction avoidance: Instead of saying “we put the database on a private network,” we say “the vector store terminus is positioned behind the zero-trust perimeter with panametric endpoint isolation.”
-
Maturity model inflation: Every problem becomes a journey through phases rather than a thing you just do.
What Actually Matters
If you’re deploying AI workloads in Azure, here’s what you actually need to decide:
-
What models, and where? Check regional availability for the models you need. This often constrains everything else.
-
How will users access it? Internal app? External API? Chat interface? This determines your front-end architecture.
-
What data will ground it? If RAG, where does that data live today, and how will you keep it current?
-
Who needs to access what? Define your identity boundaries early. Adding them later is painful.
-
What’s your budget model? AI consumption is harder to predict than traditional compute. Build in monitoring and alerts from day one.
The landing zone accelerator from Microsoft gives you IaC templates (Bicep or Terraform) that deploy a reasonable default architecture. You can start there and adjust rather than building from scratch.
But you don’t need a sixteen-week engagement to figure this out. You need someone who’s done it before, a clear understanding of your requirements, and the willingness to start simple and iterate.
Everything else is token valves.
Photo by Stephan Henning on Unsplash