Confidence Engineering - Part 4: The Variable Nobody Measures

The Weight of Getting It Wrong
What Changes When Failure Has Cost
Jerry Zhang, co-founder of Lemma, read the observability series and pushed back on something specific. The framework defines what to measure. It assumes you already know which failure modes to instrument for. His point: in production, the failures that matter most are the ones you didn’t think to write an alert for. Preset metrics only catch the problems you anticipated.
He’s right. But there’s a different question underneath his.
The fear behind his pushback isn’t about specific unknown failure modes. It’s about the existence of a boundary beyond which you cannot see. Every instrumentation strategy has that boundary. Every observability framework stops somewhere. The question isn’t whether unknown failures exist. They do. They always will. The question is what it costs when one of them finds you.
That’s consequence. And it changes everything the framework produces.
The Dimension That Was Always There
Parts 1 through 3 built a framework with five components. Each assumed something that was never stated explicitly: that the cost of failure matters.
- Observable criteria exist because being wrong has cost. You don’t define measurable conditions for a system where getting it wrong doesn’t matter.
- Instrumentation exists because unobserved failures compound cost.
- Staged authority exists because premature autonomy has cost.
- Feedback loops exist because unlearned failures repeat, and repetition multiplies cost.
- Confidence metrics exist because acting on insufficient evidence has cost.
Consequence was already driving the design of every component. Part 4 makes it explicit.
Naturally, you’d think this would be a sixth component. But it isn’t. It’s a dimension that modifies how all five behave. The same framework, applied to a low-consequence system and a high-consequence system, should produce different confidence requirements, different instrumentation depth, different authority progression rates, and different organizational posture. If it doesn’t, the framework is ignoring the variable that matters most.
A confidence score without consequence context is a number without meaning. The same failure probability carries entirely different implications depending on what failure costs.
What Consequence Does to the Components
Consequence doesn’t add new mechanics to the framework. It changes what the existing components demand depending on what’s at stake.
Observable criteria define what gives confidence in a system. Consequence changes which criteria matter and how tightly you hold them. A 95% accuracy rate on a coffee recommendation chatbot is fine. A 95% accuracy rate on inventory classification across 15,000 stores, where the entire business problem is stockouts, is not fine. Starbucks learned this in 2026 when their AI inventory tool couldn’t distinguish between milk varieties. The criteria didn’t change. The consequence context made the same criteria insufficient.
The instinct is to say the goal is zero negative consequences. That instinct is a trap. Zero is asymptotic. You never reach it. If confidence is measured by proximity to an unreachable target, you’ve built a new source of anxiety, not a new source of confidence. The more precise framing: understand what your tolerance actually is for this specific context. Consequence tells you where the threshold lives. Not at zero. At the point where failure cost exceeds organizational capacity to absorb it.
Instrumentation is where consequence meets the unknown-unknowns problem directly. How do you know what to instrument? What if you get instrumentation wrong? What if you missed something that should have existed?
These questions feel bottomless. They aren’t.
Instrumentation is always bounded by the platform the system runs on. Azure gives you a finite telemetry surface. AWS gives you a different finite surface. The platform bounds what you can observe, not what can fail. Those are different boundaries. But bounding the observation surface is still a meaningful reduction from the fear of infinite unknowns. The gap between what you instrument and what you should have instrumented doesn’t disappear, but it becomes finite and navigable rather than bottomless.
Consequence then tells you how much of that finite surface you need to cover. Low-consequence system? Instrument the obvious failure modes and iterate as you learn. High-consequence system? Instrument to the edges of what the platform can emit and build governance for what lives beyond the boundary. The depth of instrumentation is proportional to the cost of missing something.
Because instrumentation is foundational to the feedback loop, this is where consequence directly informs design requirements rather than just modifying thresholds. You aren’t adjusting a number. You’re determining how much of the system needs to be observable before you can responsibly operate it.
Staged authority is where consequences land, in the human occupying a specific seat.
Every gate in the staged authority model has a person behind it. Someone who decides whether the system advances from suggest to approve, from approve to auto. That person carries the consequence of being wrong. And the weight of that consequence changes everything about how the gate functions.
Part 3 predicted this: in cultures where failure is punished, nobody volunteers for the firing squad. The gates stay closed. The system sits in suggest mode for eighteen months. Not because confidence is low. Because the personal consequence of being wrong is too high for anyone to absorb.
That prediction describes one direction of a force that pushes both ways.
Feedback loops are where consequence changes the weight of information. The feedback loop captures the delta between expected and actual output. Without consequence, every delta is equal. A 5% deviation on a chatbot recommendation and a 5% deviation on a financial classification produce the same signal. Consequence changes that. It weights each deviation by what the gap actually cost. The feedback loop doesn’t just tell you something went wrong. It tells you how much the wrongness mattered, and that changes what the system learns from and how fast it adapts.
Confidence metrics are the aggregation of everything above. Consequence determines what the metrics need to show before anyone should act on them. A confidence score of 92% means something different when failure costs a customer mild inconvenience versus when failure triggers a regulatory investigation. The same number, read through consequence, produces different decisions. Without consequence context, a confidence metric is a number without meaning.
Consequence doesn’t just freeze decisions. It warps the entire decision space. The direction depends on which consequence the decision-maker feels most acutely.
The Force That Bends
In May 2026, Starbucks killed an AI-powered inventory tool nine months after deploying it across North America. The system used tablet cameras and LiDAR to scan shelves and automatically count beverage ingredients. It confused similar products. It missed items entirely. The tool designed to fix stockouts was creating the conditions for more stockouts.
From the outside, without any insider knowledge, the diagnostic is visible.
The failure modes weren’t exotic. Misclassifying similar products and missing items on shelves are day-one risks for computer vision in a retail environment. Any practitioner who’s worked with CV systems would identify those as the first things you test for. These weren’t unknown-unknowns that emerged in production. These were predictable failures in a context where the consequence of getting inventory wrong was the exact business problem the CEO was trying to solve.
But here’s what makes the case instructive beyond the obvious. Brian Niccol pushed this tool into stores across North America shortly after assuming the CEO role, as part of a broader turnaround campaign. The public record suggests the pressure was directional: a new CEO, a board expecting visible technology-driven improvement, ongoing stockout problems blamed for hurting sales. In that context, the consequence of NOT acting, of appearing slow while the presenting business problem persisted, would have outweighed the risk of deploying too fast.
So the system skipped staged authority entirely. No suggest phase at 100 stores. No approve phase at 1,000. Straight to full deployment. The plausible reading: organizational pressure overrode what a staged approach would have required.
This is the mirror image of the paralysis Part 3 describes. Same force. Different seat. Different direction.
When a mid-level engineer faces the gate decision, consequence pulls toward caution. The personal risk of being wrong outweighs the organizational cost of delay. Nobody gets fired for keeping the AI in suggest mode. The system freezes.
When a CEO faces the gate decision during a turnaround mandate, consequence pulls toward acceleration. The personal risk of appearing inactive outweighs the system risk of premature deployment. Nobody keeps their job by telling the board they need another six months of piloting. The system races past every gate that should have slowed it down.
Both failure modes come from consequence being assessed at the personal and political level instead of the system level. In one case, the human absorbs too much personal risk and freezes. In the other, the human absorbs too much organizational pressure and accelerates past what the evidence supports. Neither decision was informed by system-level confidence metrics. Both were driven by which consequence the decision-maker felt most acutely.
The variable isn’t the force. It’s the seat. And without something holding the decision to the evidence, the seat determines the outcome every time.
The Counterweight You Already Need
The preconditions from Part 3 aren’t just the foundation for governance. They’re the mechanism that prevents consequence from distorting every decision the framework produces.
Psychological safety means the mid-level engineer can advance a gate without career risk. The personal consequence of being wrong is bounded by a culture that treats failure as learning, not as ammunition. The gates can actually open when the evidence supports it.
Blameless culture means the CEO’s turnaround pressure doesn’t override the evidence requirements. When failure is treated as operational feedback rather than political liability, the pressure to skip stages loses its force. The gates can actually hold when the evidence doesn’t support advancement.
Honest measurement means the confidence metrics, not the political calculus, drive the decision. When the organization measures what’s actually happening instead of what leadership wants to hear, the decision-maker has something to anchor to besides their own consequence exposure.
Without these preconditions, consequence distorts the decision space in whichever direction serves the person in the seat. With them, consequence informs the decision without overriding it. The preconditions don’t eliminate consequence. They prevent it from becoming the only input.
This is why the preconditions were never optional. Parts 1 and 2 presented them as organizational health requirements. Part 3 showed what happens without them. Part 4 reveals what they were always doing: counterbalancing a force that, left unchecked, either freezes every decision or accelerates past every safeguard.
The difference with consequence is that the cost of skipping this work gets higher. When the system is low-consequence, governance theater is expensive but survivable. When the system is high-consequence, governance theater is what puts you on the front page. The organizations that do this work won’t be perfect. They’ll be prepared. And prepared, in a landscape where most competitors are performing readiness rather than building it, is a significant advantage.
The preconditions don’t make consequence disappear. They make it possible to face consequence without flinching in the wrong direction.
Preparing for What You Can’t See
Disaster preparedness professionals figured this out a long time ago.
Risk Assessment asks “what could happen” with deliberately unlimited scope. Business Impact Analysis asks “what does it cost when it does.” Architectural disaster recovery designs build the response capability. These aren’t separate practices. They’re expressions of a single question: what are the consequences of failure and are we prepared proportionally?
Consequence in this framework operates the same way.
For known failure modes, you weight specific predicted costs against your observable criteria. You instrument for them. You set thresholds based on what the organization can absorb. This is engineering. It’s bounded, measurable, and specific.
For foreseeable risks, the failures you can imagine but haven’t experienced yet, you weight categories of cost. You extend instrumentation toward the edges of the platform’s telemetry surface. You build governance review cycles that specifically look for failure patterns outside your current model. This is risk management. It’s broader, less specific, but still structured.
For genuine unknowns, the failures you can’t imagine because they haven’t happened yet, you build organizational posture proportional to what you stand to lose. You staff response capability. You build decision-making muscle through blameless postmortems and staged authority practice. You make the preconditions strong enough that when something outside your model appears, the organization can respond without panic and without paralysis.
This isn’t a spectrum you move along sequentially. All of it operates simultaneously. The known failures get specific instrumentation. The foreseeable risks get broader coverage. The genuine unknowns get organizational readiness. Consequence determines how much investment each layer gets.
A low-consequence system can tolerate gaps in all of these. A high-consequence system requires depth across all of them. That’s the proportional posture. Not perfection. Proportionality.
I’ve sat in risk assessment meetings where alien invasion was on the board with a risk score assigned. That’s not absurd. That’s the discipline working correctly. You don’t plan for every specific scenario. You build organizational posture that can absorb events you haven’t predicted yet. The risk register isn’t a prediction. It’s a posture.
What Consequence Measurement Actually Looks Like
The confidence model has clear metrics. Accuracy rates, false positive trends, intervention frequency, rollback rates, advancement and regression events. Those instruments tell you whether the system is performing. They exist across all three authority stages. They’re well understood.
What’s missing is the other instrument. Confidence tells you the system is performing at 95%. Consequence tells you what the 5% costs in this specific context. Those are two different readings of the same system, and most organizations only have the first one.
Consequence has four dimensions. Each produces a different measurement. Together they form a consequence profile that determines how tightly the confidence components need to be held.
Impact measures what happens when the system is wrong. Not whether it’s wrong. What the wrongness costs. A bad coffee recommendation is an annoyed customer who orders something else. A bad inventory classification across a national supply chain is a stockout that compounds the exact business problem the system was built to solve. Same system category. Same potential accuracy rate. Completely different consequence.
Impact is defined per capability, not per system. A single AI platform might have capabilities with wildly different impact profiles. The inventory classification capability and the shift scheduling suggestion capability don’t carry the same weight, even though they run on the same infrastructure. Treating them identically is how organizations end up over-governing low-impact capabilities while under-governing the ones that can actually hurt them.
Blast radius measures how many people, processes, or dependent systems a failure touches. This is the multiplier. A 5% failure rate affecting one store’s inventory is a manageable operational correction. The same 5% failure rate across 15,000 stores simultaneously is a supply chain event. The accuracy didn’t change. The blast radius made the same failure rate catastrophic.
Blast radius expands with authority. In suggest mode, one person evaluates one recommendation. In approve mode, a single rubber-stamped batch approval can affect hundreds of actions. In auto mode, the radius is whatever the system touches: every user, every process, every downstream dependency within the policy bounds.
Velocity measures how quickly damage compounds once a failure occurs. This is where the authority stages produce the sharpest differences. In suggest mode, damage accumulates at human speed, slow enough for the next cycle to catch and correct. In approve mode, throughput increases while review quality degrades under time pressure, and failures pass through faster than anyone looks closely. In auto mode, damage compounds at machine speed. Every execution cycle that runs with an undetected failure multiplies the cost, and the time between failure occurrence and detection is the exposure window that determines everything.
Reversibility measures whether the damage can be undone. This is the dimension that determines whether consequence is recoverable or permanent, and it changes the entire posture.
Miscounted inventory can be recounted. A customer who received the wrong drink recommendation can order again. These are reversible. The cost is real but bounded.
Leaked customer data cannot be unleaked. A financial transaction executed on misclassified information cannot always be unwound. A compliance violation reported to a regulator exists in the record permanently. These are irreversible. The cost is not just real but compounding, because irreversible failures generate their own secondary consequences: legal exposure, regulatory scrutiny, reputational damage.
Reversibility is often the dimension that should determine whether a capability ever reaches auto mode at all. Some combinations of impact, blast radius, and velocity in an irreversible domain mean the appropriate posture is permanent human oversight, no matter how high the confidence metrics climb.
The Profile in Practice
These four dimensions produce a consequence profile per capability, per authority stage. The profile isn’t a score. It’s a diagnostic that tells you whether your confidence posture matches your actual exposure.
Grant more authority and every consequence dimension climbs together. The confidence bar has to climb with it.
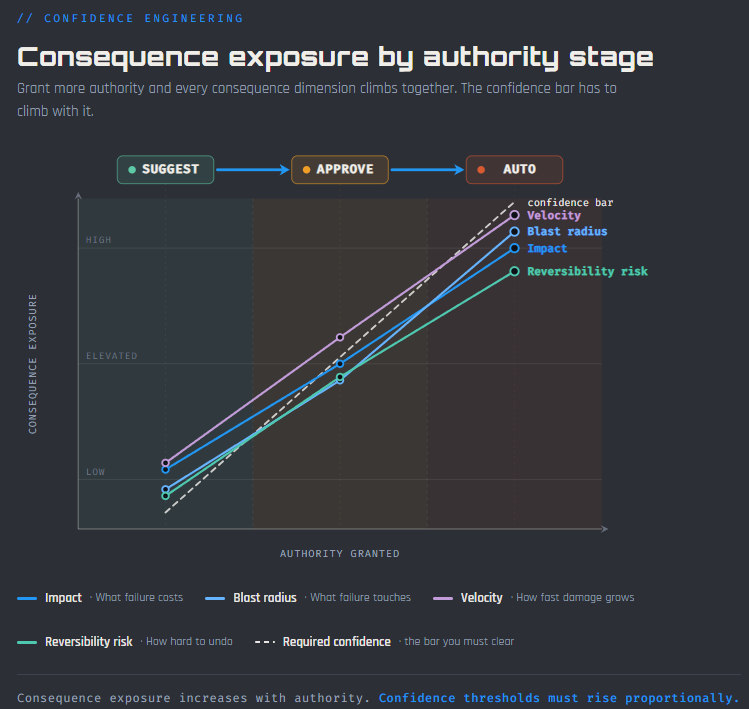
The graph reveals something the component descriptions alone can’t show. As authority increases from suggest through approve to auto, every consequence dimension rises. Impact becomes unmediated. Blast radius expands to the full scope of the system. Velocity accelerates from human speed to machine speed. Reversibility risk grows as the window to intervene shrinks.
The confidence bar, the dashed line above every consequence dimension, is the threshold you must clear before granting that level of authority. It always sits above the consequence lines. It has to.
But here’s what matters most: the gap between the confidence bar and the consequence lines never closes. As long as a human is in the decision chain, there’s always a delta between what the system can prove about itself and what the consequences actually are. That gap is not a flaw. It’s the space where human judgment lives. The human exists in the loop precisely because the system can’t fully close the distance between “I measured my performance” and “I understand what my failures cost in this context.”
The only theoretical convergence point, where confidence and consequence fully align without a gap, requires removing the human entirely. Full autonomy. That’s an observation, not a destination.
For practitioners operating real systems today, the work is about keeping the gap proportional. Small enough that the system is useful. Large enough that a human can still intervene meaningfully. If the gap gets too large, the system is over-governed and stalls. If the gap gets too small, you’ve effectively handed over full authority without formally acknowledging it.
The framework defines the structure. It tells you what to measure and how those measurements interact with your authority model. It doesn’t force implementation. But if you want the outcomes, you must establish the practice that produces and maintains them. Define the targets. Build the capability to meet them. Measure the gap between confidence and consequence. Close it proportionally or accept the exposure with eyes open.
The confidence model tells you the system is working. The consequence profile tells you what it costs if the confidence model is wrong. You need both instruments, and the space between them, to make a defensible decision.
The Pursuit
None of it works without understanding what failure costs.
Consequence is the force that acts on every component of the framework. It changes which criteria matter. It determines how deeply you instrument. It warps the decision space around every person sitting at a staged authority gate. It’s the reason the preconditions exist.
And it never resolves. There is no point at which you’ve fully accounted for consequence. New failure modes emerge. Business context shifts. The person in the seat changes. The organizational pressure changes. The cost of being wrong changes.
This is not a framework you implement and forget. It’s a practice you sustain. The pursuit is relentless because consequence is relentless. The goal isn’t to arrive at perfect confidence. It’s to build the organizational capacity to face consequence continuously, adjust continuously, and learn continuously.
It’s messy. It will always be messy. Because consequence is human. The systems are technical, but the force that distorts decisions, the fear of being wrong, the pressure to act, the weight of accountability, all of it is human. It was human before AI. It will be human after whatever comes next.
The framework doesn’t clean that up. It gives you a structure for operating inside the mess without pretending it’s clean.
Next in Series: Confidence Engineering - Part 5: Confidently Execute Authority →
This is Part 4 of the “Confidence Engineering” series. View full series. Part 3: Adoption Déjà Vu covers why adoption fails even when the practice exists.
Photo by Sunder Muthukumaran on Unsplash