Confidence Engineering - Part 5: Confidently Execute Authority

Confidently Execute Authority
When the Gate Becomes the Bottleneck, Just Open the Gate
Parts 1 through 4 built a framework for knowing whether to act. Confidence Engineering replaces the unanswerable question of whether to trust AI with an engineering question: what would give you confidence, and can you measure it. Observable criteria. Instrumentation. Staged authority. Feedback loops. Confidence metrics. Then consequence as the dimension that modifies how all five behave. Each part answered a question the previous part left open.
None of them specified what a system that acts on those measurements looks like.
That gap didn’t matter when the framework was applied to human teams adopting AI capabilities. Humans gate themselves. They slow down when they’re uncertain, escalate when the stakes are high, and build intuition through repetition. The framework gave them structure for doing what they were already doing informally.
Multi-agent orchestration doesn’t have that luxury. Agents don’t slow down when they’re uncertain. They don’t escalate based on intuition. They execute at the speed the orchestrator allows, and the only thing between that execution and production is whatever gate the system puts in front of it. The current gate model for most agent orchestration systems is uniform: a human approval step at every handoff. Every unit of agent work, regardless of what it is, how well understood it is, or what it costs if it’s wrong, funnels through the same review queue.
That model contains a contradiction it cannot resolve on its own. If every handoff requires human approval, the human is a serial constraint sitting in front of a parallel system. The system was purchased to compress timelines through parallel execution. The gate model prevents the compression it’s supposed to protect. Parallel execution and uniform gating are structurally incompatible, and nobody is talking about it honestly.
Organizations hitting the bottleneck respond in one of two ways, and both of them fail.
The Two Wrong Responses
The first response is to remove the gates. The human reviewer is the constraint, so eliminate the constraint. Let the agents execute. Ship faster. The dashboards look great for ninety days. Adoption metrics climb. Timelines compress. Leadership presents the numbers at quarterly review and everyone agrees the investment is paying off.
Then something breaks in production that nobody caught because nobody was looking. The failure isn’t small, because the gates that would have caught it were the ones you removed. Leadership says the organization “lost trust in the AI.” They’re right about the loss, wrong about the frame. What collapsed was the evidence base that justified letting the system operate. The whole program gets pulled back, not to the gated model, but further. Back to manual. Back to “we tried AI and it didn’t work.” The 88% that adopted just lost one more from the 6% that were getting value.
The second response is to keep the gates and accept the throughput ceiling. Every unit of agent work still funnels through a human reviewer. The parallel execution engine runs in front of a serial approval queue. Timelines compress, but only marginally, and they hit a ceiling well below what the system was sold to deliver. The reviewer is the constraint regardless of how many agents are working upstream. Nobody calls it a failure. It just quietly gets deprioritized in the next budget cycle because the ROI never materialized against the promise. It dies of indifference rather than incident.
Both responses share the same structural error. They treat the gate as binary: present or absent, on or off. The gate exists uniformly at every handoff, or it doesn’t exist at all. That binary is the disease, not the agents or the orchestration layer sitting underneath them. The assumption that governance is a single switch, applied identically to every piece of work regardless of what that work is, what confidence exists in its quality, and what it costs if it’s wrong.
The 88% of organizations using AI and the 6% capturing enterprise value are not separated by technology selection, vendor choice, or executive sponsorship. They are separated by whether their governance model can distinguish between work that needs a human and work that doesn’t. The ones that can’t distinguish are choosing between reckless and useless. The ones that can are building something that actually scales.
The answer isn’t a better gate. It’s a different unit of governance.
The Unit of Governance Moves
The binary fails because it governs at the wrong level. Uniform gating treats every unit of agent work as equally risky. Remove the gates entirely and you treat every unit as equally safe. Neither is true. The work coming out of a multi-agent system is not homogeneous. Some of it is well understood, repeatedly validated, operating against low-impact targets. Some of it is novel, operating in unfamiliar context, touching systems where the cost of being wrong is severe. Governing both identically is the structural error.
The unit of governance moves from the agent handoff to the task type. Not “did an agent produce this,” but “what kind of work is this, how much evidence exists that this kind of work holds downstream, and what does it cost if it doesn’t.”
That’s three variables. A confidence score derived from observed outcomes for this task type. A blast radius representing the impact if the output is wrong. And a threshold, governed and auditable, that determines how those two interact to produce a routing decision. The gate doesn’t disappear. It becomes selective. And the selection is governed by calibrated evidence rather than by a uniform policy that cannot distinguish between a formatting change and a schema migration.
Three routing lanes emerge from this logic. Work with no calibration history, where the task type is novel or the context is unfamiliar, always routes to a human. That’s the mandatory gate. It exists because confidence without evidence is assumption, and assumption does not get to auto-pass into production. Work below the threshold routes to human review. The reviewer is targeted rather than saturated, seeing the work that actually needs judgment rather than drowning in a queue of work that doesn’t. Work above the threshold, where the task type has demonstrated across engagements that its output holds downstream, proceeds automatically with logged sampling for audit and outcome measurement.
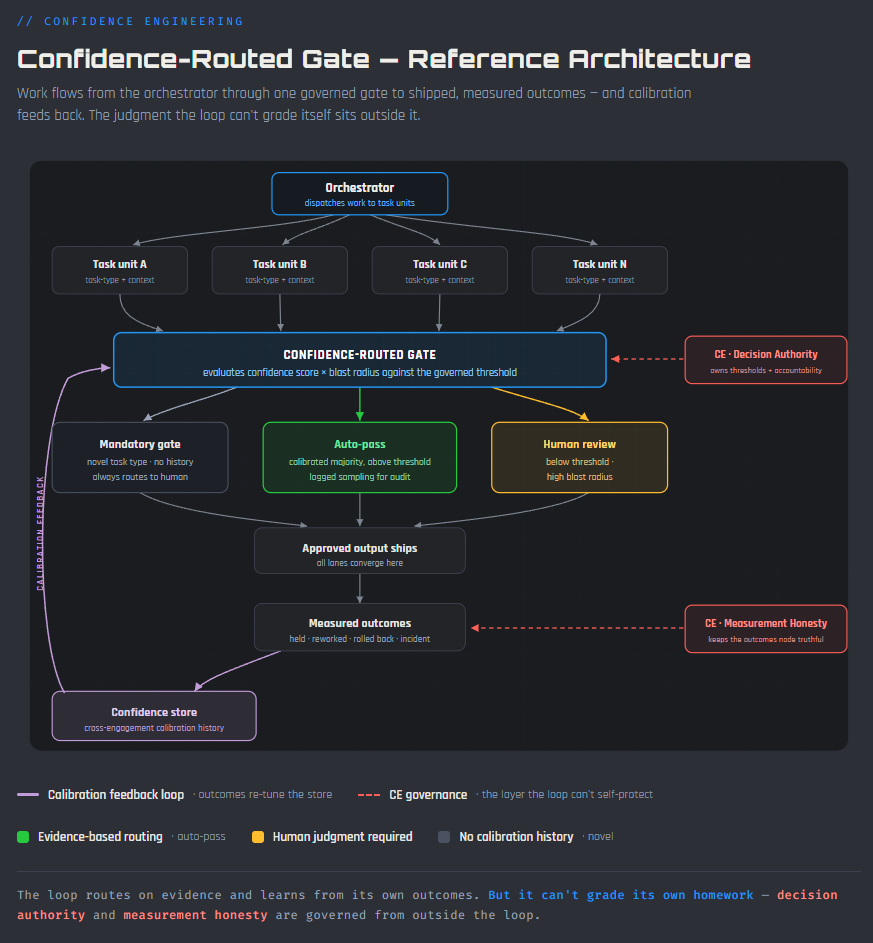
The proportions shift over time. Early in an engagement, most work is novel. The mandatory gate dominates. As task types accumulate outcome history and earn their thresholds, the calibrated majority migrates toward auto-pass and the human reviewer concentrates on the genuinely risky minority. The system gets faster as it gets smarter, not because anyone lowered the bar, but because evidence accumulated to justify the speed.
The progression through the lanes is the earned-advancement model from the series applied to task types instead of human teams. Mandatory-gate is calibration. Human-review is calibrated. Auto-pass is fluency. Regression drops a task type back when outcomes deteriorate. The system learns in both directions, and the progression is encoded into the system rather than left as organizational policy.
The gate didn’t open. The work earned its way through.
The Score and the Multiplier
The confidence score deserves its own scrutiny, because it’s the variable doing the most work and the one most likely to be gamed.
The score is per task type and per context class. It is not a single global number. It is not a model self-report. Model self-reported confidence is known to be poorly calibrated, and relying on it as the routing input is exactly what a commodity gate would do. The score that matters is calibrated from observed outcomes. Each task type accumulates a history of whether its output held downstream: did it ship clean, require rework, trigger a rollback, cause an incident. That history, held in a cross-engagement confidence store, sets and adjusts the threshold the gate applies.
A task type earns its way into the auto-pass lane by demonstrating, repeatedly, that its output holds. A task type that starts failing downstream loses its threshold and routes back to human review. The store doesn’t care about the agent’s self-assessment. It cares about what happened after the output shipped.
The natural question is how many successful outcomes a task type needs before it earns its way forward. The honest answer is that no universal number exists. A formatting task type operating against low-blast-radius targets might earn auto-pass after a few dozen clean outcomes. An infrastructure change against production systems with regulatory exposure might require hundreds. The minimum sample size before a threshold is meaningful is a function of blast radius and organizational risk tolerance, which makes it a governance decision, not an engineering constant. What matters is that the number is explicit, governed, and auditable, not informal.
Blast radius multiplies the score before routing. This is deliberate. Confidence alone would auto-pass confident mistakes into production. A high-confidence change to a high-blast-radius target still gates, because the cost of a confident error on that target is large. A lower-confidence change to a trivial, reversible target can auto-pass, because the cost of being wrong is absorbable. Confidence tells you how likely the output is to hold. Blast radius tells you what happens if it doesn’t. The product of the two is what the gate actually evaluates.
The Loop and Its Vulnerabilities
Everything described so far is buildable by any competent engineering team. The routing logic is not exotic. The feedback loop is not proprietary. The confidence store is a database with an outcome schema. None of this, on its own, is a defensible position. It’s plumbing.
The plumbing becomes dangerous without governance, and this is where the framework earns its place.
A self-calibrating feedback loop is only as honest as the measurement feeding it. Approved output ships. Downstream outcomes get measured. Those measurements recalibrate the scores the gate uses. The loop improves with use. It also calibrates itself confidently wrong if the measurement feeding it is dishonest, performative, or quietly redefined between evaluation periods.
“Did it hold downstream” is the single point of failure for the entire system. If outcome measurement is gamed, if “held” gets redefined to exclude inconvenient rework, if the metrics are presented without the context that would make them interpretable, the confidence store calibrates on fiction. The gate begins auto-passing failures behind a score that looks calibrated. That’s worse than no gate at all, because it carries the authority of evidence it didn’t earn.
This is the problem Measurement Honesty solves. It governs the outcomes node that feeds the confidence store. Without it, the feedback loop launders bad work behind a calibrated number.
The second vulnerability is the threshold itself. Someone decides when a task type graduates from human-review to auto-pass. Someone decides how blast radius maps to authority levels. If that decision is informal, thresholds drift, scope creeps, and nobody owns the expansion of AI autonomy within the system. The orchestrator gets faster without anyone having decided it should.
This is the problem Decision Authority solves. But authority without accountability is just permission. Someone owns the decision to promote a task type, and someone is accountable for what that promotion produces downstream. Task types earn promotion on demonstrated outcomes through a governed workflow, not on pressure to ship faster or on informal consensus that “it seems fine.” When a promoted task type fails in auto-pass, the accountability trail leads back to the evidence package that justified the promotion and the person who approved it. That’s not punitive. That’s how governed systems learn.
Without these two, the routing loop is a liability pretending to be a control. With them, the loop stays honest as it scales. That’s not a feature difference. That’s the difference between a system you can operate in production and a system that will eventually auto-pass its way into an incident nobody saw coming.
The loop is commodity. The governance that keeps it honest is not.
Consequence at the Gate
Blast radius is consequence made computable. It’s the operational expression of Part 4’s argument pushed into the routing logic where it actually affects decisions.
A 95% confidence score on a reversible, low-exposure formatting change means the output almost certainly holds and the cost of being wrong is trivial. Auto-pass. A 95% confidence score on an irreversible schema migration in a regulated system means the output almost certainly holds, but the cost of the remaining 5% is severe. Human review. Same score. Different consequence. Different routing decision.
Without blast radius in the product, confidence alone makes the routing decision, and confidence alone will auto-pass confident mistakes into production. The multiplication is what prevents the gate from being naive. The gap between confidence and consequence is where human judgment lives. The gate formalizes that gap. The human occupies it when the gap is wide. The system handles it when the gap is narrow.
Part 4 said consequence changes what every component demands. This is what that looks like when the component is a gate.
What’s Unsolved
What’s unsolved is worth stating. The framework gets better through use and feedback, not through waiting until it’s perfect.
The cold start problem is real. A new task type has no outcome history. It enters at mandatory-gate by design. But how many labeled calibration points does it need before it can leave? Set the minimum too low and task types graduate on insufficient evidence. Set it too high and the mandatory gate becomes the same bottleneck the system was designed to remove. The answer is probably context-dependent rather than universal, which means it’s a governance decision, not an engineering constant.
Novelty detection is unsolved. Where does a task type end and a new one begin? If a code generation task type has earned auto-pass in one context class, does a similar but not identical context inherit that calibration or start fresh? Too coarse and genuinely new work slips into auto-pass on borrowed confidence. Too fine and everything is perpetually novel. The boundary between variant and genuinely new is a judgment call that needs a governed answer.
Blast radius scoring needs a concrete rubric. The concept is clear: scope of the change, reversibility, exposure of the affected system, regulatory weight. The computation is not. If blast radius is subjective, the product of confidence and blast radius is not reproducible across engagements, and the routing decision becomes inconsistent. Making it consistent without making it reductive is an open design problem.
Threshold governance needs operational definition. Decision Authority owns thresholds in principle. The actual workflow, who reviews promotion requests, on what cadence, with what evidence package, needs to be specified. This overlaps with the broader question of how confidence engineering operationalizes at scale, which the series has identified but not yet fully answered.
These are real gaps. Naming them is not a weakness in the framework. It’s the framework doing what it should: observe, question, iterate, challenge, verify.
The governance problem with multi-agent orchestration is not that agents make mistakes. Everything makes mistakes. Mistakes are operational reality, not a disqualifying condition.
The problem was that governance had no mechanism for acting on what the framework measures. Observable criteria existed. Instrumentation existed. Staged authority, feedback loops, confidence metrics, consequence, all of it existed. What didn’t exist was a system that takes those inputs and makes a routing decision, per task, on calibrated evidence, without requiring a human at every handoff or trusting an agent at every handoff.
That mechanism now has a shape. A gate that routes on the product of confidence and consequence. A feedback loop that recalibrates on observed outcomes. Governance that keeps the loop honest at the two nodes it cannot protect on its own. And a progression model where authority is earned, not assumed, and where accountability follows the decision back to the evidence that justified it.
The series started with a reframe: confidence, not trust. It built a practice. It diagnosed why adoption fails even when the practice exists. It surfaced the dimension that was driving everything from the start. Part 5 is what the system that acts on all of it looks like.
The framework is complete. Now the real work begins. That was always the point.
Photo by Possessed Photography on Unsplash